MySQL架构
mysql客户端连接服务端
通信类型:同步,(客户端操作简单)
连接方式:长连接(使用完放回连接池)
客户端的一个会话就是服务端的一个线程。
服务端默认的最大连接数:151,可修改的最大的:100000
参数有两个级别:global(全局的) session
通信方式:半双工通信,在一个连接里面不能同时发送和接受,
默认的数据包大小:max_allowed_packet 4m大小
查询的时候避免没有limit 的语句。
查询缓存
但是比较鸡肋,如果查询的sql语句多一个空格或者大小写不一样,就从查询缓存中找不到了,或者说如果缓存中有一条数据更新,整个缓存就没有了。
paser解析器
解析sql语句的词法语法,将语句按照关键字打碎,构造成一个树的结构,叫做解析树。
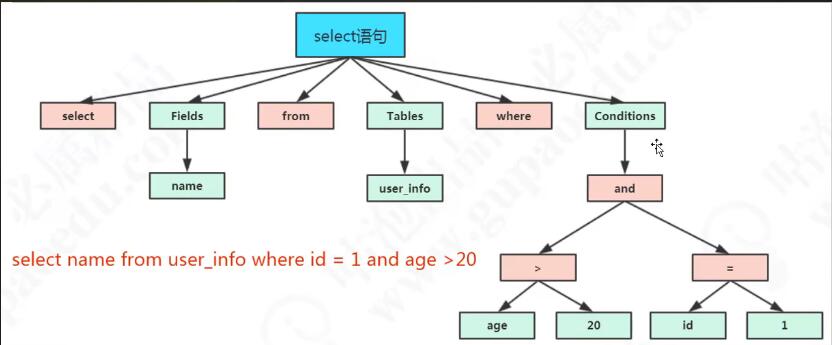
preprocessor 预处理
语义解析的功能,权限的解析
如果说是查询一个不存在的表,他是在解析的时候报错。
执行方式:客户端发送一个sql语句可能有很多执行方式。
optimizer 优化器
对sql语句进行解析,得到execution plans 执行计划
execution plans 执行计划
数据库三大范式
第一范式:当关系模式R的所有属性都不能再分解为更基本的数据单位时,称R是满足第一范式,即属性不可分
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,即非主属性不传递依赖于键码
存储引擎
单位是表
InnoDB:
InnoDB是一个事务型的存储引擎,有行级锁定和外键约束。
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级别这类型的文章。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
适用场景:
经常更新的表,适合处理多重并发的更新请求。
支持事务。
可以从灾难中恢复(通过bin-log日志等)。
外键约束。只有他支持外键。
支持自动增加列属性auto_increment。
索引结构:
InnoDB也是B+Treee索引结构。Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
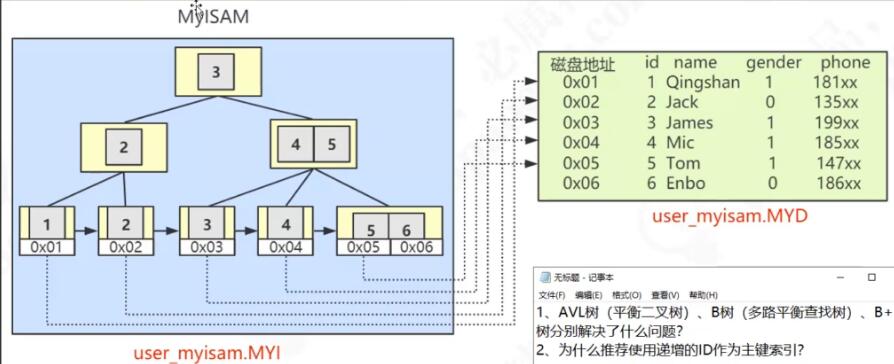
MylASM
MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT或UPDATE数据时即写操作需要锁定整个表,效率便会低一些。MyIsam 存储引擎独立于操作系统,也就是可以在windows上使用,也可以比较简单的将数据转移到linux操作系统上去。
适用场景:
不支持事务的设计,但是并不代表着有事务操作的项目不能用MyIsam存储引擎,可以在service层进行根据自己的业务需求进行相应的控制。
不支持外键的表设计。
查询速度很快,如果数据库insert和update的操作比较多的话比较适用。
整天对表进行加锁的场景。
MyISAM极度强调快速读取操作。
MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
缺点:就是不能在表损坏后主动恢复数据。
索引结构:
MyISAM索引结构:MyISAM索引用的B+ tree来储存数据,MyISAM索引的指针指向的是键值的地址,地址存储的是数据。B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。
Memory:数据存储在内存中,快,但是容易丢失数据。
3、InnoDB和Mylsam的区别:
1)事务:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持,提供事务支持已经外部键等高级数据库功能。
2)性能:MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快。
3)行数保存:InnoDB 中不保存表的具体行数,也就是说,执行select count() fromtable时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count()语句包含where条件时,两种表的操作是一样的。
4)索引存储:对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。MyISAM支持全文索引(FULLTEXT)、压缩索引,InnoDB不支持。
MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB存储它的表&索引在一个表空间中,表空间可以包含数个文件(或原始磁盘分区)。这与MyISAM表不同,比如在MyISAM表中每个表被存在分离的文件中。InnoDB 表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上。
5)服务器数据备份:InnoDB必须导出SQL来备份,LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
MyISAM应对错误编码导致的数据恢复速度快。MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
6)锁的支持:MyISAM只支持表锁。InnoDB支持表锁、行锁 行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
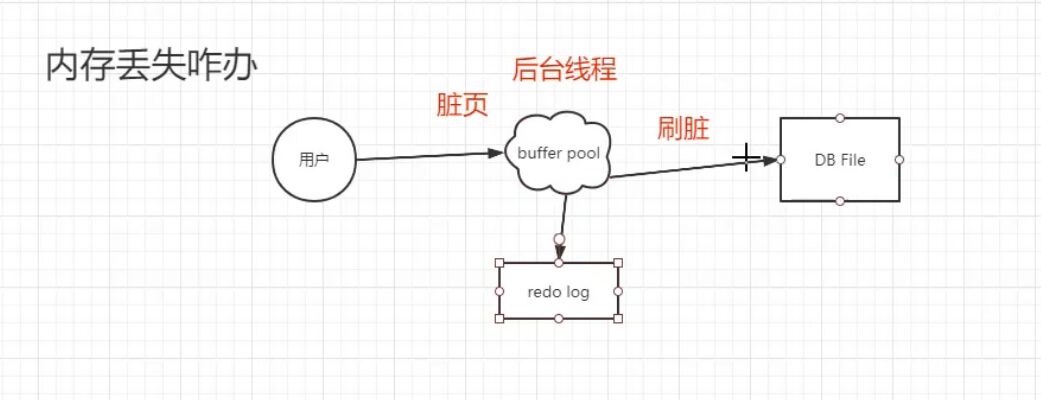
写redo日志比写数据库文件快?这样效率是不是变低了
数据库文件:随机I/O
redo日志:顺序I/O,物理日志
A undo log :原子性 逻辑日志
存储引擎把数据加载到内存之后要干什么?
1、把磁盘或者内存的数据返回给server层
2、修改值
3、undo log 、redo log
4、调用存储引擎的接口,在buffer pool 修改对应的值
5、事务提交
server层binary log文件的作用
主从复制
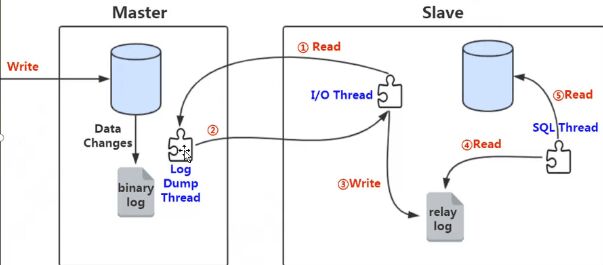
更新语句的执行流程
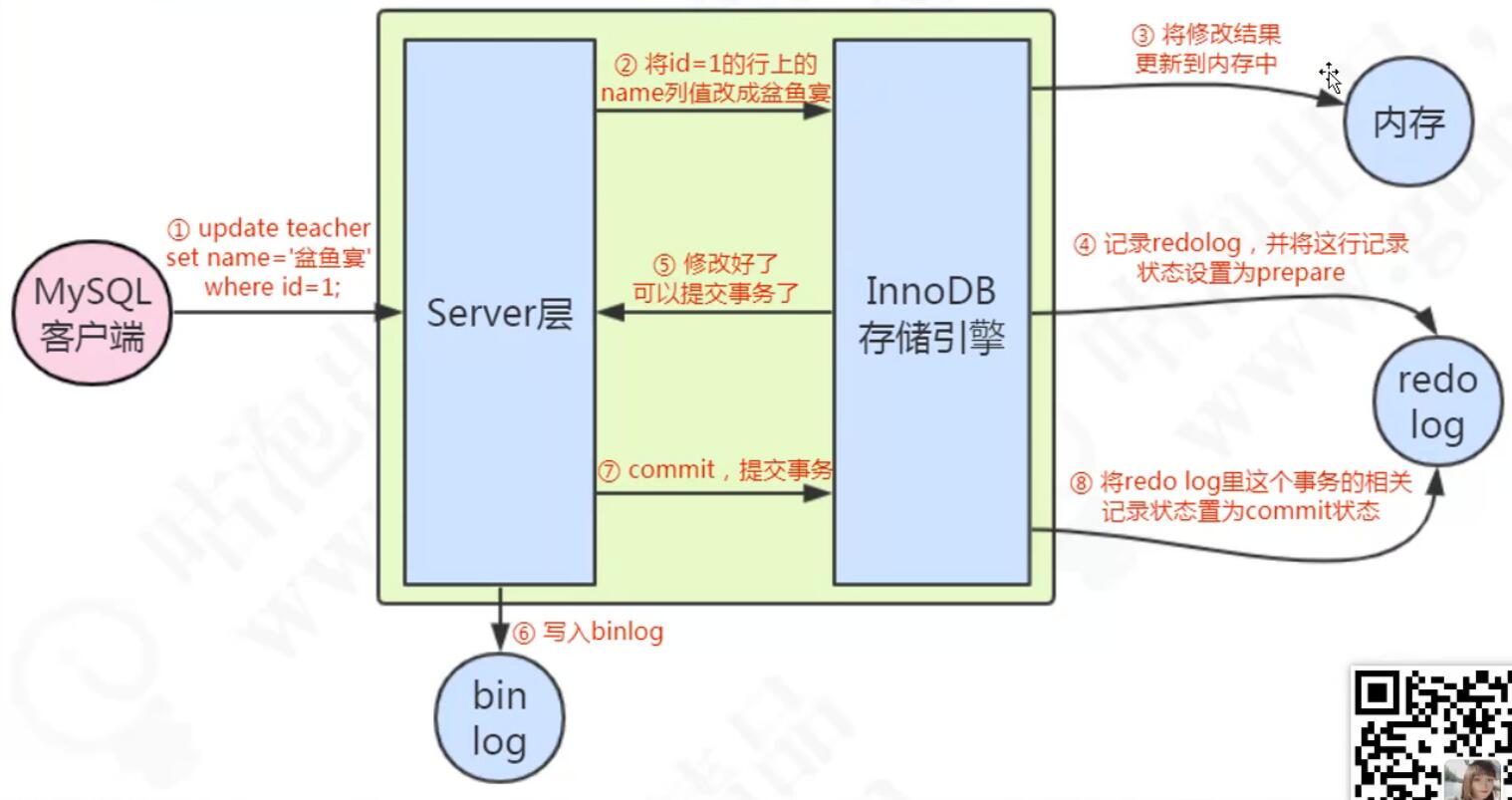
MySQL索引原理
数据库索引:是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中的数据。
AVL树解决了什么问题
解决了平衡二叉树在插入有序数据的时候,导致左右树的深度差过于大。左旋,右旋操作
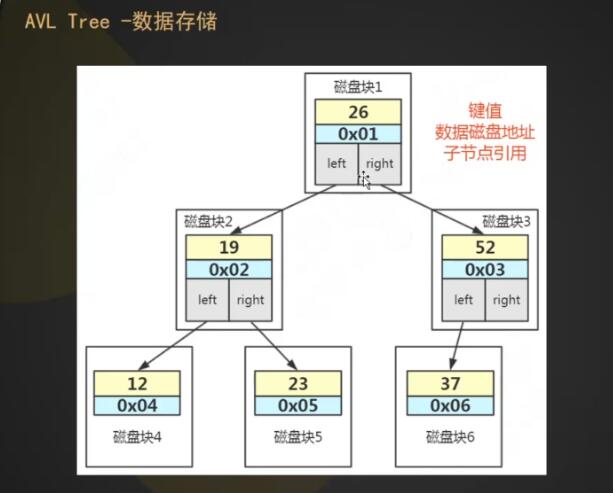
每读取一个节点,就要对磁盘io进行一次操作,读取16kb的数据。而且每个节点的数据可能是很小的,这是一个很大的浪费。
如果用节点把每一页的16kb填满,从一个瘦高的树变成一个矮胖的树,这就是优化后的多路平衡查找树。
多路平衡查找树(Balanced Tree B树)
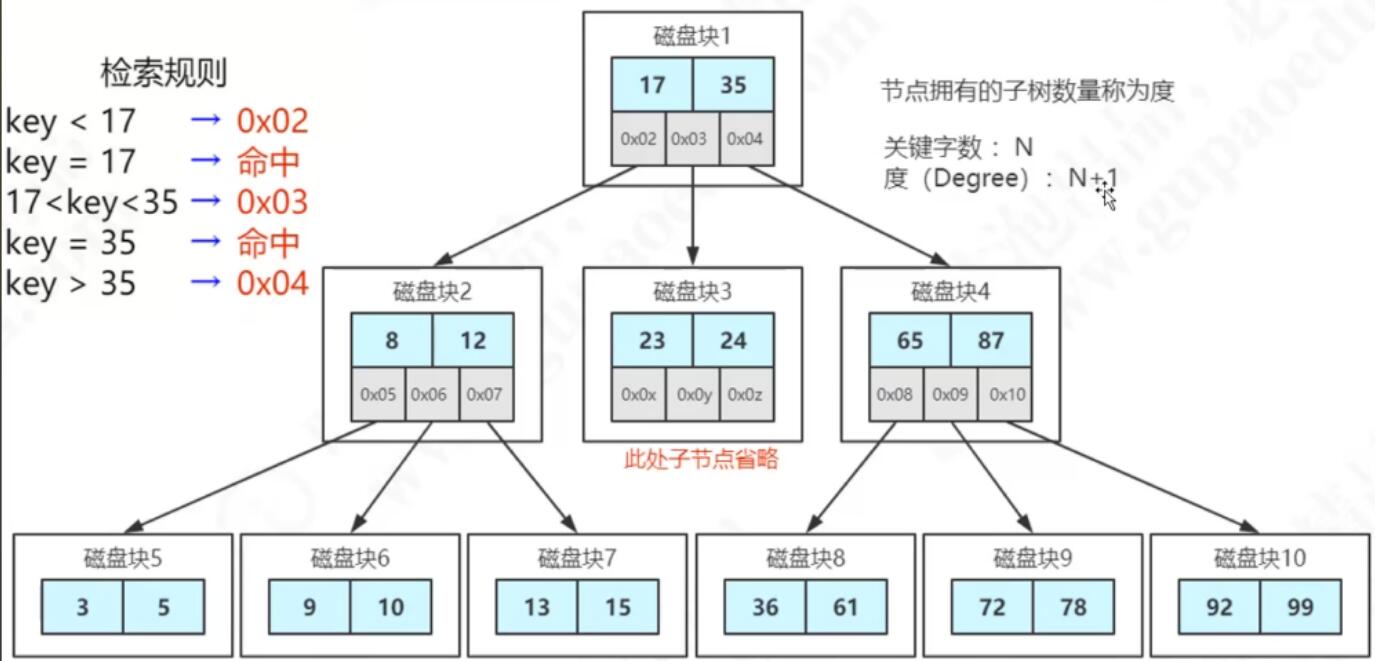
通过分裂和合并操作来构造B Tree
每个节点存放的关键字个数为n,则它的度最大为n+1
B+树 加强版多路平衡查找树
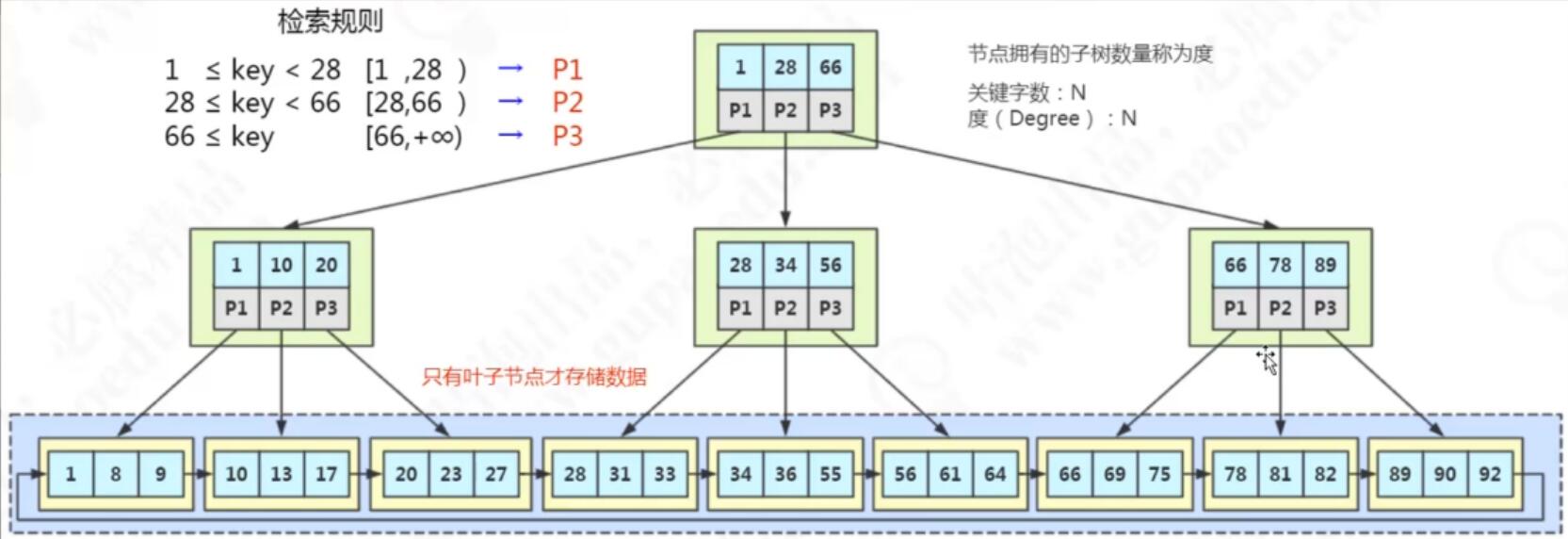
特性:
只把数据存放在叶子节点,这样上面就可以存放更多的键值和更多的度,树的高度就变低了。
并且给所有的叶子节点加了双向指针,这样查询的值在相邻的几个叶子节点上的时候,就不需要多次从根节点开始进行遍历,只需要从其中一个叶子节点开始遍历相邻的叶子节点就好了。
优势:
- B Tree能解决的问题,B+ Tree都能解决
- 扫库、扫表能力更强
- 磁盘读写能力更强
- 排序能力更强
- 效率更加稳定
哈希索引
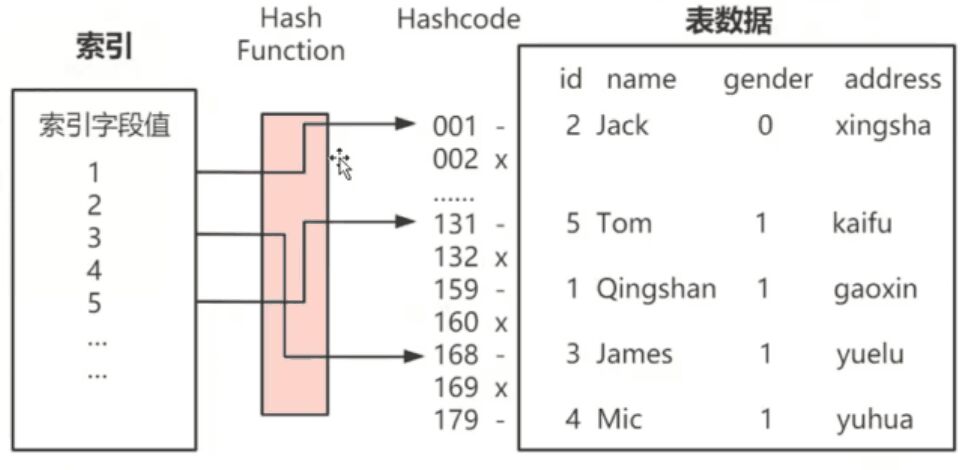
缺点:无序的,如果key值重复,就要解决哈希冲突的问题。
只适合一些特殊的场合。
索引在不同的存储引擎中的实现
MyISAM-主键索引
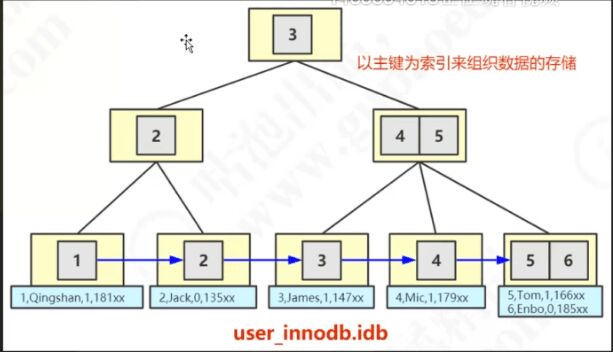
InnoDB
数据和索引都存储在叶子节点上
索引组织表,索引就是数据,数据就是索引
聚簇索引:索引的逻辑顺序和完整数据行的物理顺序是一致的
主键索引一定是聚簇索引,其他的索引都是非聚簇索引
一张表可以没有索引吗?
1、有主键
2、no null unique key
3、row_id
辅助索引
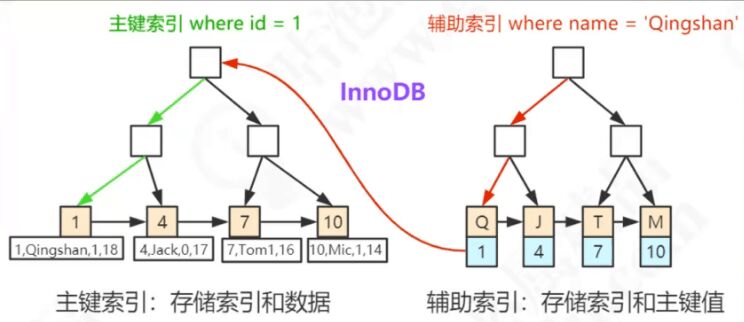
联合索引的最左匹配原则
是按照最左边的关键字进行排序的
MySQL事务与锁机制详解
事务性
事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
数据库事物的四大特性
原子性:原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。undo log来实现
一致性:一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
隔离性:隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。锁和MVCC机制
持久性:持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。redo log
事务的隔离级别
在并发事务访问数据库时,可能会存在三个问题
- 脏读:脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
- 不可重复读:不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
- 幻读:幻读是事务非独立执行时发生的一种现象。例如事务T1读取一条指定where条件的语句,返回结果集。此时事务T2插入一行新记录,恰好满足T1的where条件。然后T1使用相同的条件再次查询,结果集中可以看到T2插入的记录,这条新纪录就是幻想。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
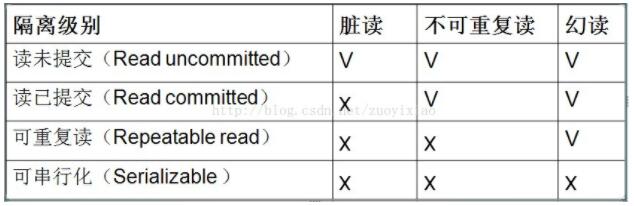
隔离级别
READ_UNCOMMITTED 读未提交:最低级别,一个事务可以读取另一个未提交事务的数据。幻想读、不可重复读和脏读都允许。
READ_COMMITTED 读已提交:一个事务要等另一个事务提交后才能读取数据。允许幻想读、不可重复读,不允许脏读。
REPEATABLE_READ 可重复读:在开始读取数据(事务开启)时,不再允许修改操作。允许幻想读,不允许不可重复读和脏读。
SERIALIZABLE 可串行化:最高级别,在该级别下,事务串行化顺序执行。幻想读、不可重复读和脏读都不允许。
解决方案
1、在读取数据前,对其加锁,阻止其他事务对数据进行修改。
2、生成一个数据请求时间点的一致性数据快照,并用这个快照来提供一定级别的一致性读取(MVCC),快照他会放在undo log里面。(不加锁的select)

InnoDB锁的基本类型
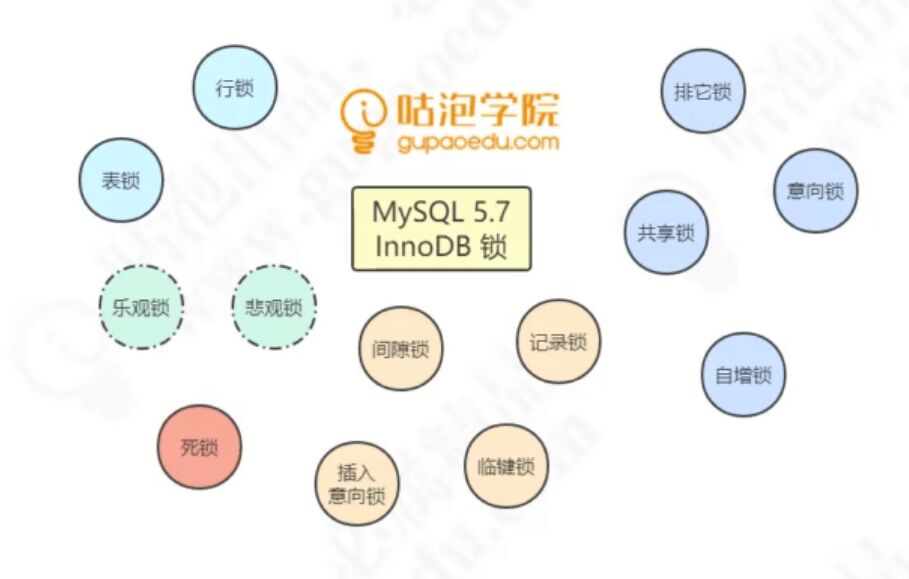
行锁与表锁的区别
锁定粒度:表锁 > 行锁
加锁效率:表锁 > 行锁
冲突概率:表锁 > 行锁
并发性能:表锁 < 行锁
行锁:共享锁
又称读锁,允许多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
行锁:排它锁
又称写锁,不能与其他锁并存,只有获取了该排它锁的事务才可以对数据进行修改和读取。
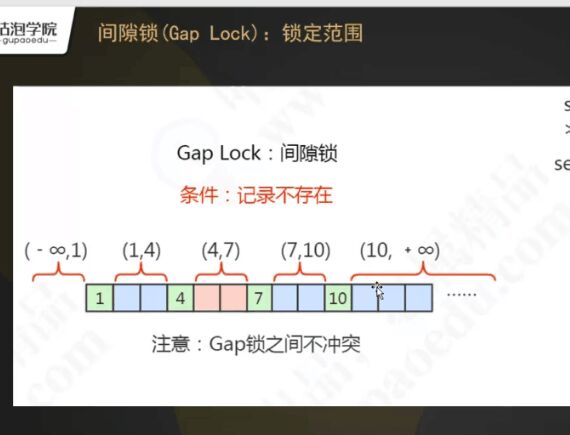
间隙锁
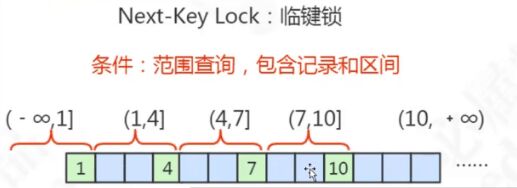
临建锁
一个事务的锁在什么时候会释放呢?
在事务结束的时候。