关联容器
无序的关联容器(链式哈希表)O(1)
- unordered_set : 无序集合 只存储key,不允许key重复的
- unordered_multiset : 无序多重集合 只存储key,允许key重复
- unordered_map : 无序映射表 存储key-value,不允许key重复
- unordered_multimap:无序多重映射表 存储key-value,允许key重复
有序的关联容器(红黑树)O(logn)
- set : 无序集合 只存储key,不允许key重复的
- multiset : 无序多重集合 只存储key,允许key重复
- map : 无序映射表 存储key-value,不允许key重复
- multimap:无序多重映射表 存储key-value,允许key重
使用场景判断:基本上使用的都是无序的关联容器,只有在对key值的有序性有要求的应用场景,才需要用到有序的关联容器
写完没保存,全没了,心态崩了.jpg
哈希表(散列表):如果一组数据,通过一种映射方式,能够找到该数据存储的位置,那么支持这种映射关系存储数据的数据结构(表)。
哈希表:除留余数法=》哈希函数/散列函数
怎么解决哈希冲突?
1.线性探测法
2.链地址法(拉链法)=》链式哈希表 无序关联容器
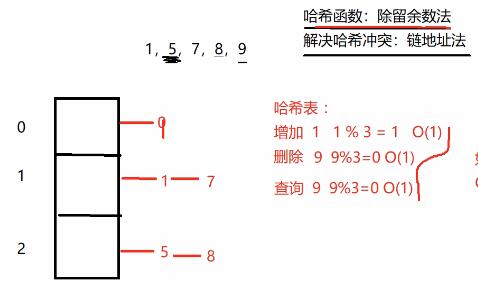
如果桶里面的链表太长,定位到哈希桶以后,还得在链表的搜索上耗费时间。
(1)所选择的哈希函数一定要能够把元素离散均匀的放到各个桶中
(2)有一个衡量哈希表使用情况的参数,称作加载因子loadfactor
当已被占用的桶的个数/桶的总数>0.75,哈希表就需要扩容了
哈希表扩容以后,原来哈希表中的元素需要重新扩容吗?
需要,代价还是挺高的,但是直接把链表的节点摘下来连到新的节点上,这样看代价也不是很高。
写了个框架,后面补完。。。(已更新)
1 |
|